参考资料:菜鸟教程
创建数据库
实例
use 创建数据库1
2
3
4> use runoob //如数据库不存则创建,否则切换到制定数据库
switched to db runoob
> db //显示当前操作的数据库
runoob
show dbs 查看所有数据库
1 | > show dbs //如果数据库中没有数据,则不会显示出来 |
insert 插入数据
1 | > db.runoob.insert({"name":"lyctea"}) |
删除数据库
语法
删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名1
db.dropDatabase()
实例
删除数据库 runoob
首先,查看所有数据库:
1 | > show dbs |
接下来我们切换到数据库 runoob:
1 | > use runoob |
执行删除命令:
1 | > db.dropDatabase() |
最后,我们再通过 show dbs 命令数据库是否删除成功:
1 | > show dbs |
删除集合
集合删除语法格式如下:
1 | db.collection.drop() //collection 是集合名 |
以下实例删除了 runoob 数据库中的集合 runoob:
1 | > show tables |
插入文档
文档的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON
插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
1 | db.COLLECTION_NAME.insert(document) |
实例
以下文档可以存储在 MongoDB 的 runoob 数据库 的 col 集合中:
1 |
|
查看已经插入的文档,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
1 | > db.col.find() |
定义一个变量,插入数据库中
1 | > document = {title: 'is a var',description: 'use test'} |
插入文档你也可以使用 db.col.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档
update() 方法
用于更新已经存在的文档
语法格式
1 | db.collection.update( |
实例
我们在集合 col 中插入如下数据:
1 | > db.col.insert({title:'jiaocheng',class: 'yuwen'}) |
修改多条文档
1 | > db.col.update({title:'jiaocheng'},{$set:{title:'MongoDB'}},{multi:true}) |
save()方法
save()方法通过传入的文档来替换已有文档,语法格式如下
1 | db.collection.save( |
实例:
以下实例中我们替换了 _id 为 597005c9c1f1597f764b41bb 的文档数据:
1 | > db.col.save({_id: ObjectId('597005c9c1f1597f764b41bb'),title: 'changeById',by:'lyctea'}) |
更多实例
1 | //只更新第一条记录: |
删除文档
MongoDB remove()函数是用来移除集合中的数据。
MongoDB数据更新可以使用update()函数。
在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
语法
remove() 方法的基本语法格式如下所示:
1 | db.collection.remove( |
实例
移除title 为 MongoDB的文档
1 | > db.col.remove({title:'MongoDB'}) |
查询文档
MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档
语法
MongoDB 查询数据的语法格式如下:
1 | db.collection.find(query, //可选,使用查询操符制定查询条件; |
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
1 | >db.col.find().pretty() //pretty() 方法以格式化的方式来显示所有文档。 |
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。
语法格式如下1
>db.col.find({key1:value1, key2:value2}).pretty()
实例:
以下实例通过class和title健来查询数据1
2> db.col.find({'class':'yuwen'},{'title':'peixun'}).pretty()
{ "_id" : ObjectId("5970093bc1f1597f764b41bd"), "title" : "peixun" }
MongoDB OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:1
2
3
4
5
6
7>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
实例
以下实例通过class或者title健来查询数据1
2
3
4
5
6> db.col.find({$or:[{'class':'yuwen'},{'title':'peixun'}]}).pretty()
{
"_id" : ObjectId("5970093bc1f1597f764b41bd"),
"title" : "peixun",
"class" : "yuwen"
}
AND 和 OR 联合使用
联合条件查询,查询likes大于50,并class为语文或者title为peixun的文档 (>50&&(class==yuwen || title==peixun))
1 | > db.col.find({'likes':{$gt:50},$or:[{'class':'yuwen'},{'title':'peixun'}]}).pretty() |
MongoDB条件操作符
描述
条件操作符,用于比较两个表达式并从mongoDB集合中获取数据
MongoDB中条件操作符有:1
2
3
4 -$gt 大于
< -$lt 小于
= -$gte 大于等于
<= -$lte 小于等于
清空集合的数据1
2 db.col.remove({})
WriteResult({ "nRemoved" : 3 })
插入以下数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 db.col.insert({
... title: 'PHP 教程',
... description: 'PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。',
... by: '菜鸟教程',
... url: 'http://www.runoob.com',
... tags: ['php'],
... likes: 200
... })
WriteResult({ "nInserted" : 1 })
db.col.insert({title: 'Java 教程',
... description: 'Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。',
... by: '菜鸟教程',
... url: 'http://www.runoob.com',
... tags: ['java'],
... likes: 150
... })
WriteResult({ "nInserted" : 1 })
db.col.insert({title: 'MongoDB 教程',
... description: 'MongoDB 是一个 Nosql 数据库',
... by: '菜鸟教程',
... url: 'http://www.runoob.com',
... tags: ['mongodb'],
... likes: 100
... })
WriteResult({ "nInserted" : 1 })
mongoBD (>)操作符 -$gt
获取col集合中,likes大于100的数据,你可以使用一下命令1
2
3 db.col.find({likes: {$gt: 100}})
{ "_id" : ObjectId("597197fa6d266472131059b0"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("597198106d266472131059b1"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
mongoDB (>=)操作符 -$gte
获取col集合中,likes大于等于100的数据1
db.col.find({likes: {$gte: 100}})
mongoDB (<)小于操作符 -$lt1
>db.col.find({likes: {$lt: 100}})
mongoDB (<=)小于等于操作符 -$lte1
db.col.find({likes: {$lte: 100}})
同时使用大于和小于条件查询语句1
2 db.col.find({likes: {$lt: 200, $gt: 100}})
{ "_id" : ObjectId("597198106d266472131059b1"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
MongoDB $type操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果
MongoDB中可以是使用的类型如下: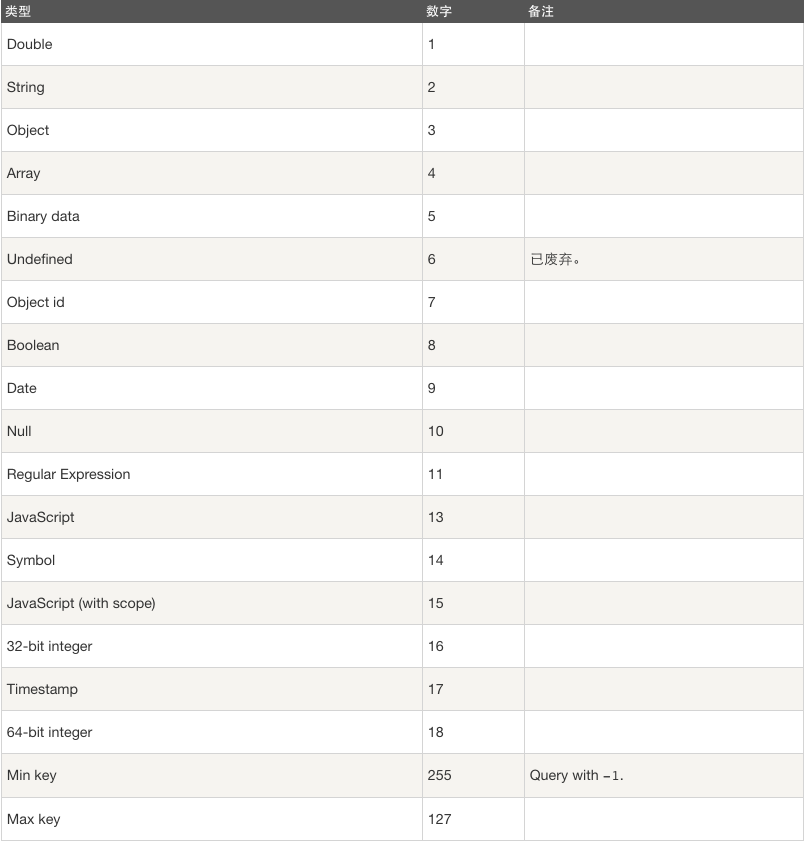
实例
获取col集合中title为String的数据,可以使用以下命令, type的健值对对照上图
1
2
3
4 db.col.find({title: {$type: 2}})
{ "_id" : ObjectId("59719c336d266472131059b3"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("59719c386d266472131059b4"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("59719c416d266472131059b5"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB Limit与Skip方法
如果需要在MongoDB中,读取指定数量的数据记录,可以使用MongoDB的Limit方法,该方法接受一个参数,该参数指定从MongoDB中读取的记录条数
Limit
语法
1 | db.COLLECTION_NAME.find().limit(NUMBER) |
实例
1 | > db.col.find({},{title:1, _id:0}).limit(2) |
Skip
语法
1 | db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) |
实例
以下实例之后显示第二条文档数据1
2 db.col.find({},{title:1,_id:0}).limit(1).skip(1)
{ "title" : "Java 教程" }
MongoDB排序
语法
1 | >db.COLLECTION_NAME.find().sort({KEY:1}) |
实例
col集合按照likes的降序排列
1 | > db.col.find({},{title:1,_id:0}).sort({likes: -1}) |
MongoDB 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
ensureIndex()方法创建索引
MongoDB使用 ensureIndex() 方法来创建索引。
语法
1 | >db.COLLECTION_NAME.ensureIndex({KEY:1}) |
实例
ensureIndex()title升序创建索引,降序则为-11
2
3
4
5
6
7> db.col.ensureIndex({title:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
也可以使用多个字段来创建索引
1 | > db.col.ensureIndex({title: 1, description: -1}) |
ensureIndex() 接收可选参数,可选参数列表如下:
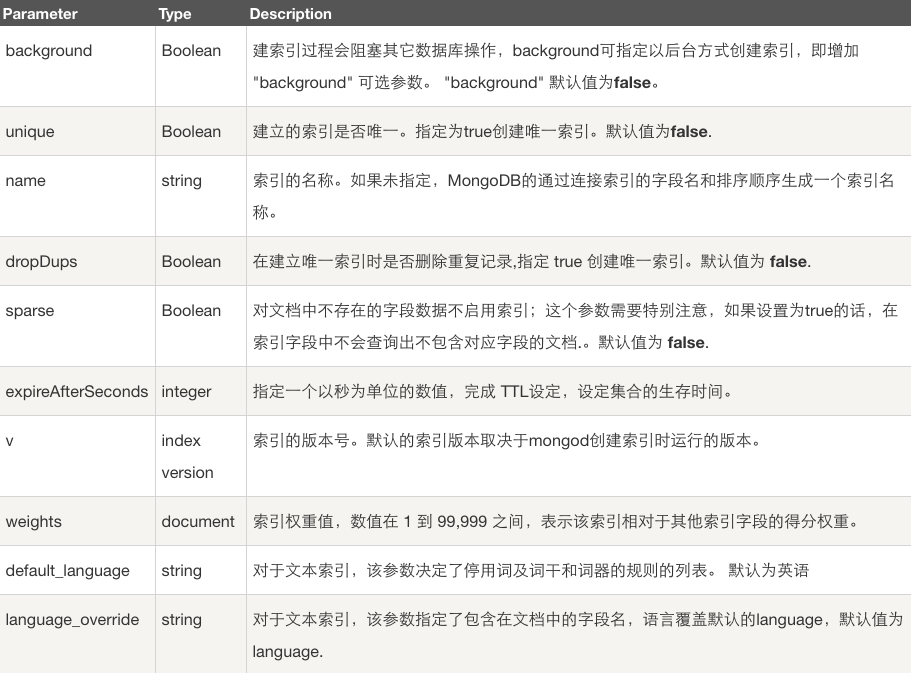
实例:
1 | > db.values.ensureIndex({open: 1, close: 1}, {background: true}) |
MongoDB聚合
MongoDB中聚合(aggregate)主要用于处理数据(统计平均值,求和),并返回计算后的数据结果。
aggregate()方法
语法
1 | >db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION) |
实例
计算集合中,每个title的数量1
2
3
4> db.col.aggregate([{$group: {_id: '$title', total: {$sum: 1}}}])
{ "_id" : "MongoDB 教程", "total" : 1 }
{ "_id" : "Java 教程", "total" : 1 }
{ "_id" : "PHP 教程", "total" : 1 }
常用的聚合表达式
1 | 表达式 描述 实例 |
管道的概念
管道在Unix和Linux中一般用于当前命令的输出结果作为下个命令的参数
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作可以重复
表达式:处理输入文档并输出,表达式是无状态的,只能用于计算当前聚合管道中的文档,不能处理其他文档
聚合框架中常用的几个操作:
1 | $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 |
管道操作实例
查询结果,只包含title和rul字段,1 表示包含,0表示不包含1
2
3
4> db.col.aggregate({$project: {title:1,url:1,_id: 0}})
{ "title" : "PHP 教程", "url" : "http://www.runoob.com" }
{ "title" : "Java 教程", "url" : "http://www.runoob.com" }
{ "title" : "MongoDB 教程", "url" : "http://www.runoob.com" }
$match用于获取likes大于100的记录,然后将符合条件的记录送到一下阶段$group管道操作进行处理1
2> db.col.aggregate([{$match: {likes: {$gt: 100}}},{$group:{_id: null,title: {$sum: 1}}}])
{ "_id" : null, "title" : 2 }
经过$skip管道符处理后,前两个文档被过滤掉了
1 | > db.col.aggregate({$skip: 2}) |
MongoDB复制(副本集)
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储副本,提高了数据的可用性,并可以保证数据安全。
复制还可以允许从硬件故障和服务终端中恢复数据。
什么是复制
- 保障数据的安全性
- 提高数据可用性
- 灾难恢复
- 无需停机维护(如备份,重建索引,压缩)
- 分布式读取数据
MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,复制处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongoDB个节点常见搭配方式为: 一主一从,一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取的这些操作,然后对自己的数据副本执行这些操作,从而保证节点的数据与主节点一致
MongoDB复制结构图如下: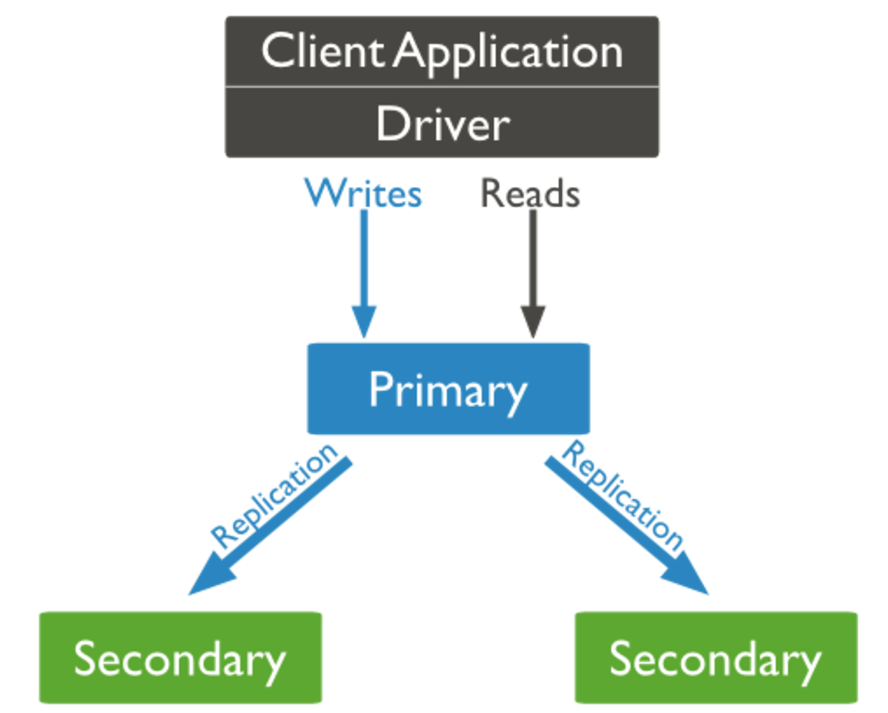
以上结构图总,客户端总主节点读取数据,在客户端写入数据到主节点是, 主节点与从节点进行数据交互保障数据的一致性。
副本集特性
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
MongoDB副本设置
在教程中使用同一个MongoDB来做MongoDB的主从实验,步骤:
关闭正在运行的Mongo服务器
现在我们通过指定 –replSet 选项来启动mongoDB。–replSet 基本语法格式如下:
1 | mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME" |
实例
1 | mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0 |
以上实例会启动一个名为rs0的MongoDB实例,其端口号为27017。
启动后打开命令提示框并连接上mongoDB服务。
在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。
我们可以使用rs.conf()来查看副本集的配置
查看副本集状态使用 rs.status() 命令
副本集添加成员
添加副本集的成员,我们需要使用多条服务器来启动mongo服务。进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
语法
rs.add() 命令基本语法格式如下:
1 | >rs.add(HOST_NAME:PORT) |
实例
假设你已经启动了一个名为mongod1.net,端口号为27017的Mongo服务。 在客户端命令窗口使用rs.add() 命令将其添加到副本集中,命令如下所示:
1 | >rs.add("mongod1.net:27017") |
MongoDB中你只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster() 。
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。